この記事は、
SettingwithCopyWarning: How to Fix This Warning in Pandas – Dataquest
の日本語訳です。3回にわたって掲載予定で、この記事は1回目です。

前書き
pandasを書いていたら、SettingWithCopyWarningという警告が出てきた。
うーん。やりたい動作はできてるように見えるし、何がまずいんだかいまいち分からん。
と思って、いつものように警告の名前でググってみると、以下の記事(英語)を発見した。
SettingwithCopyWarning: How to Fix This Warning in Pandas – Dataquest
これはすごい。
この警告についてめっちゃ詳しく書いてある。後半ではpandasの歴史まで立ち入って解説している。
その充実した内容に感嘆すると同時にびっくりした。
日本語では詳しい解説をしている記事が見つからなかった。
SettingWithCopyWarningについて俺が適当な記事を書くよりも、この記事をちゃんと訳したほうがよい。
どう考えてもそのほうが良い。俺のためにもなるし、読む人のためにもなるでしょ!
……と思って翻訳の許可を申し出たところ、快諾をいただいたので、翻訳した。
Google翻訳をベースにしたが、そこから全面的に修正している。この記事を含めて3つに分ける予定である。翻訳が完了し次第、順次公開する予定である。
それでは本文へどうぞ。
本編 はじめに
SettingWithCopyWarningは、pandasを学ぶときに遭遇する最も一般的な困難の1つである。ザッとウェブ検索してみると、Stack Overflowの質問、GitHubのissue、フォーラムの投稿が山のように見つかるだろう。この警告が自分たちの特定の状況で何を意味するのかについて、何とか理解しようとしているプログラマーからのものだ。 多くの人がこれに苦労しているのは当然のことだ。pandasのデータ構造に対するインデックス操作の方法は非常にたくさんあり、それぞれが固有のニュアンスを持っている。pandas自体さえ、同一に見えるかもしれない2行のコードが、同じ結果になることを保証していないのだ。
このガイドでは、警告が生まれる理由とそれを解決する方法について説明する。また、何が起こっているのかをより理解してもらうための内部的な詳細な説明も行う。そして、この話題に関するいくつかの歴史的な経緯も述べていくので、なぜこのように動作するのかについて視点が得られるだろう。
SettingWithCopyWarningを調査するために、以降ではデータセットを使って説明する。eBay上で3日間のオークションでXboxが販売されたときの価格のデータセットであり、書籍 『モデリングオンラインオークション』から引用した。
それでは見てみよう:
import pandas as pd
data = pd.read_csv('xbox-3-day-auctions.csv')
data.head()
| - |
auctionid |
bid |
bidtime |
bidder |
bidderrate |
openbid |
price |
| 0 |
8213034705 |
95.0 |
2.927373 |
jake7870 |
0 |
95.0 |
117.5 |
| 1 |
8213034705 |
115.0 |
2.943484 |
davidbresler2 |
1 |
95.0 |
117.5 |
| 2 |
8213034705 |
100.0 |
2.951285 |
gladimacowgirl |
58 |
95.0 |
117.5 |
| 3 |
8213034705 |
117.5 |
2.998947 |
daysrus |
10 |
95.0 |
117.5 |
| 4 |
8213060420 |
2.0 |
0.065266 |
donnie4814 |
5 |
1.0 |
120.0 |
ご覧のとおり、このデータセットの各行は、ある特定のeBay Xboxオークションへの1回の入札に関するものだ。以下は各列の簡単な説明である。
auctionid - 各オークションの一意の識別子。bid - 入札の金額。bidtime - オークションの中で入札した時間(日単位)。bidder - 入札者のeBayユーザー名。bidderrate - 入札者のeBayユーザー評価。openbid - オークションのために売り手が設定した始値。price - オークション終了時の落札価格。
SettingWithCopyWarningとは何か?
最初に理解しておくべきことは、SettingWithCopyWarningは警告であり、エラーではないということだ。
エラーは、何かが壊れていることを示している。例えば無効な構文や、未定義の変数を参照しようとしていることなどだ。一方で、警告の役目は、プログラマの注意を喚起して、コードの中にある潜在的なバグや問題に気づかせることである。警告は出るが、このコードは言語仕様の中で許可されている操作である。この場合、警告は重大ではあるが目立たない間違いを暗示している可能性が非常に高い。
SettingWithCopyWarningが伝えていることは、操作が期待どおりに機能しなかった可能性があること、そして、結果を確認して間違いがないことを確かめる必要があることである。
警告が出ていてもコードが期待した通りに動いている場合は、警告を無視したくなるかもしれない。 これは悪い習慣であり、SettingWithCopyWarningを決して無視してはいけない。 対策を講じる前に、しばらく時間をかけてなぜ警告が発生しているのかを理解しよう。
SettingWithCopyWarningがどういうものかを理解するために、分かっていると役に立つことがある。それは、pandasのいくつかの動作がデータのビューを返す可能性があること、そして他の動作がコピーを返すということだ。
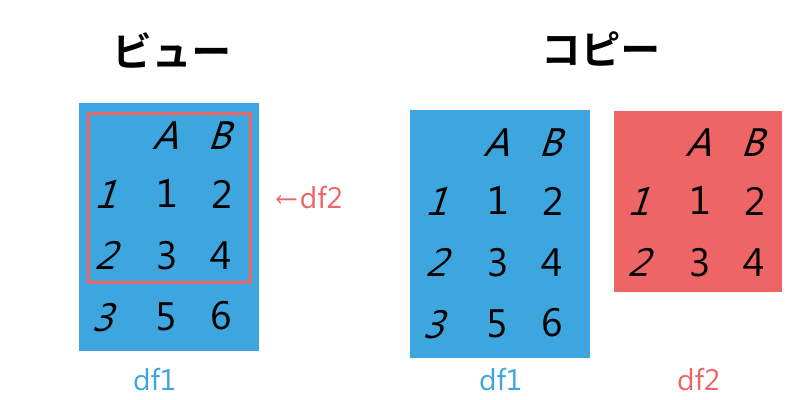
上の図からわかるように、左側のビューdf2は元のdf1のサブセットにすぎないが、右側のコピーは新しい単一のオブジェクトdf2を作成している。
値を変更しようとすると、両者の違いのせいで問題が起きる恐れがある。
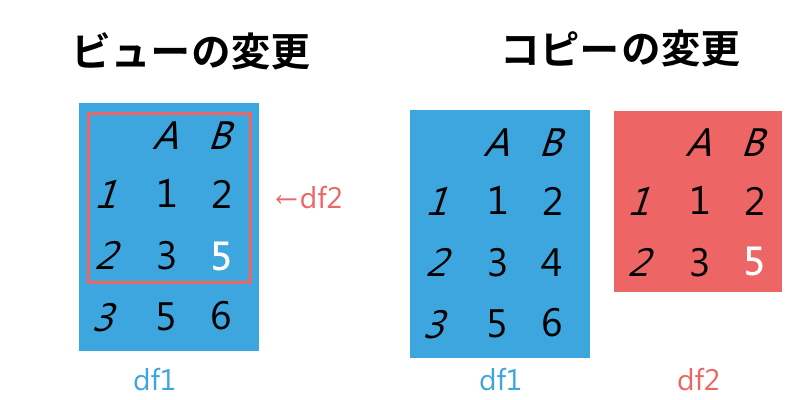
私たちがしていることによるが、元のdf1を修正したい(左側)かもしれないし、df2だけを修正したい(右側)かもしれない。 警告が知らせていることは、私たちがどちらか一方を実行してほしかったのに、コードがもう片方を実行した可能性があるということだ。
これについては後で詳しく説明するが、ここでは、警告の2つの主な原因とその解決方法について説明をする。
連鎖代入
pandasは連鎖代入(chained assignment)と呼ばれるものを検出すると警告を発生する。説明のために使用する用語をいくつか定義しよう。
- 代入(Assignment) - あるものの値を設定する操作。例えばdata = pd.read_csv('xbox-3-day-auctions.csv') 。 しばしばセット(set)と呼ばれる。
- アクセス(Access) - あるものの値を返す操作。例えば、以下のインデックス作成と連鎖の例のような操作。 しばしばゲット(get)と呼ばれる。
- インデックス(Indexing) - データのサブセットを参照する代入またはアクセスのメソッド。 例えばdata[1:5]。
- 連鎖 - 複数のインデックス操作を連続して使用すること。 例えばdata[1:5][1:3]。
連鎖代入は、連鎖と代入の組み合わせである。先ほどロードしたデータセットを使った例を簡単に見てみよう。後ほど、もっと詳しくこの件を調査していく。説明の都合上、ユーザー'parakeet2004'の入札者の評価が間違っていると言われたため、更新する必要がある、と仮定しよう。はじめに、現在の値を見てみよう。
data[data.bidder == 'parakeet2004']
| - |
auctionid |
bid |
bidtime |
bidder |
bidderrate |
openbid |
price |
| 6 |
8213060420 |
3.00 |
0.186539 |
parakeet2004 |
5 |
1.0 |
120.0 |
| 7 |
8213060420 |
10.00 |
0.186690 |
parakeet2004 |
5 |
1.0 |
120.0 |
| 8 |
8213060420 |
24.99 |
0.187049 |
parakeet2004 |
5 |
1.0 |
120.0 |
bidderrateのフィールドを更新する必要があるのは3行である。では次に、実際に更新してみよう。
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ipykernel/__main__.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
if __name__ == '__main__':
なんてこった。不思議なことに、SettingWithCopyWarningに出くわしてしまった!
調べてみると、今回の場合、値は変更されていないことが分かる。
data[data.bidder == 'parakeet2004']
| - |
auctionid |
bid |
bidtime |
bidder |
bidderrate |
openbid |
price |
| 6 |
8213060420 |
3.00 |
0.186539 |
parakeet2004 |
5 |
1.0 |
120.0 |
| 7 |
8213060420 |
10.00 |
0.186690 |
parakeet2004 |
5 |
1.0 |
120.0 |
| 8 |
8213060420 |
24.99 |
0.187049 |
parakeet2004 |
5 |
1.0 |
120.0 |
警告が発生したのは、2つのindexing操作を連鎖させたためだ。今回は角括弧を2回使用したので、容易に見つけられるが、.bidderrate 、 .loc、 .iloc、.ix[]などの他のアクセス方法を使用した場合も同様である。 連鎖操作は
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
だ。これら2つの連鎖操作は、順番に独立して実行される。1つ目はアクセスメソッド(get操作)である。これは、bidderが'parakeet2004'と等しいすべての行を含むDataFrameを返す。2番目は代入操作(セット操作)であり、この新しいDataFrameに対して呼び出されている。決して、元のDataFrameを操作しているのではない。
解決策は簡単だ。すなわち、元のDataFrameがsetされたことをpandasが保証できるように、 locを使用して連鎖操作をまとめて、単一の操作にする。以下のような連鎖のないset操作がうまく動作することを、pandasは常に保証している。
data.loc[data.bidder == 'parakeet2004', 'bidderrate'] = 100
data[data.bidder == 'parakeet2004']['bidderrate']
6 100
7 100
8 100
Name: bidderrate, dtype: int64
私たちがこのように対処することを警告は提案している。そして今回の場合、それは完璧に上手くいく。
隠れた連鎖
次に、SettingWithCopyWarningに遭遇する2番目に一般的な方法について説明する。落札できた入札を調査しよう。それらを処理するための新しいdataframeを作成する。連鎖代入についての教訓を学んだので、今後はlocを使用するように注意する。
winners = data.loc[data.bid == data.price]
winners.head()
| - |
auctionid |
bid |
bidtime |
bidder |
bidderrate |
openbid |
price |
| 3 |
8213034705 |
117.5 |
2.998947 |
daysrus |
10 |
95.00 |
117.5 |
| 25 |
8213060420 |
120.0 |
2.999722 |
djnoeproductions |
17 |
1.00 |
120.0 |
| 44 |
8213067838 |
132.5 |
2.996632 |
*champaignbubbles* |
202 |
29.99 |
132.5 |
| 45 |
8213067838 |
132.5 |
2.997789 |
*champaignbubbles* |
202 |
29.99 |
132.5 |
| 66 |
8213073509 |
114.5 |
2.999236 |
rr6kids |
4 |
1.00 |
114.5 |
続けて、winnersという変数を処理するコードを何行か書くかもしれない。
mean_win_time = winners.bidtime.mean()
...
mode_open_bid = winners.openbid.mode()
偶然にも、 DataFrameに別の間違いがあるのを発見した。今度は、304というラベルの行のbidderの値が欠損している。
winners.loc[304, 'bidder']
nan
説明の都合上、この入札者の本当のユーザー名を知っていて、データを更新したと仮定しよう。
winners.loc[304, 'bidder'] = 'therealname'
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/indexing.py:517: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
self.obj[item] = s
またもやSettingWithCopyWarningだ! しかし、私たちはlocを使ったのだ、それなのにどうしてまたこの警告が起きたのだろうか? 調べるために、コードの結果を見てみよう。
print(winners.loc[304, 'bidder'])
therealname
今回はうまくいっている。それでは、なぜ警告が表示されたのだろうか。
連鎖インデックスは、1行の中だけでなく2行にわたって発生する可能性がある。 winnersはget操作( data.loc[data.bid == data.price] )の出力として作成されたため、元のDataFrameのコピーかもしれないし違うかもしれないが、確認してみるまでどちらか知るすべが無かったのだ!私たちがwinnersのインデックス操作をするとき、実際には連鎖インデックスを使っていた。
つまり、 winnersを変更しようとしたときに、dataも同時に変更されている可能性があるということだ。
実際のソフトウェア開発をするときのコードでは、遠く離れた2つの行によって連鎖インデックスが起きる可能性があるため、問題の原因を突き止めることはより難しいかもしれないが、状況は同じことである。
この場合に警告を防ぐための解決策は、新しいdataframeを作成するときに、コピーを作成するようpandasに明示的に指示することである。
winners = data.loc[data.bid == data.price].copy()
winners.loc[304, 'bidder'] = 'therealname'
print(winners.loc[304, 'bidder'])
print(data.loc[304, 'bidder'])
therealname
nan
これだけのことだ!簡単な話である。
秘訣は、連鎖インデックスを特定し、何としてもそれを回避することだ。元々のデータを変更したい場合は、単一の代入操作を使うこと。コピーが欲しいなら、pandasにコピーを作るように命令するのを忘れないこと。これによって時間は節約できるし、あなたのコードは堅牢になる。
また、 SettingWithCopyWarningはsetをしているときに限り発生するが、 getに対しても連鎖インデックスは避けることを勧める。 連鎖操作は速度が遅いし、後から代入操作を追加することにした場合は問題が発生するだろう。
これで元々の記事全体の3分の1くらいだな……この後の部分も頑張って翻訳中だ。
ご意見・ご感想・励ましのお便りをお待ちしています。
2019年5月18日 追記:
2回目
linus-mk.hatenablog.com
3回目
linus-mk.hatenablog.com
